
Overview
Right Place, Right Time! Dynamizing Topological Graphs for Embodied Navigation
Embodied navigation methods commonly operate in static environments with stationary targets. In this work, we present a new algorithm for navigation in dynamic scenarios with non-stationary targets. Our novel Transit-Aware Strategy (TAS) enriches embodied navigation policies with object path information. TAS improves performance in non-stationary environments by rewarding agents for synchronizing their routes with target routes. To evaluate TAS, we further introduce Dynamic Object Maps (DOMs), a dynamic variant of node-attributed topological graphs with structured object transitions. DOMs are inspired by human habits to simulate realistic object routes on a graph. Our experiments show that on average, TAS improves agent Success Rate (SR) by 21.1 in non-stationary environments, while also generalizing better from static environments by 44.5% when measured by Relative Change in Success (RCS).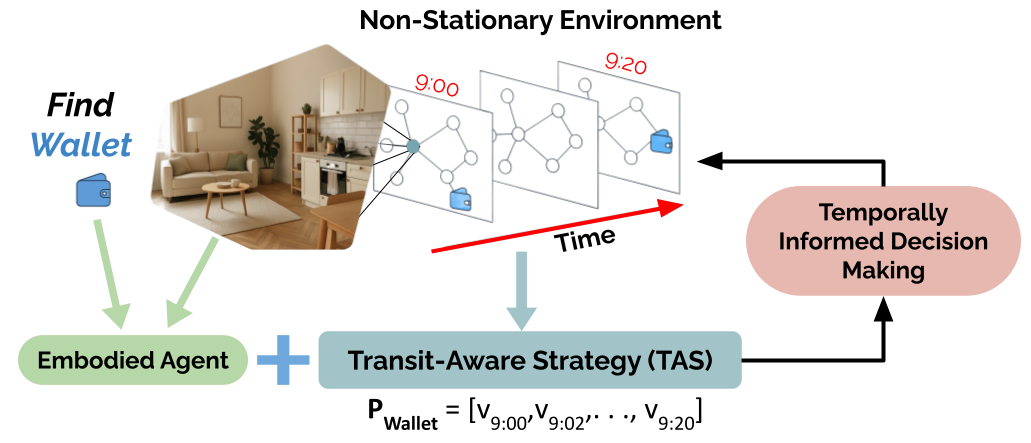
Paper
Right Place, Right Time! Dynamizing Topological Graphs for Embodied Navigation.
Vishnu Sashank Dorbala, Bhrij Patel, Amrit Singh Bedi, Dinesh Manocha
Is the House Ready for Sleeptime? Generating and Evaluating Situational Queries for Embodied Question Answering
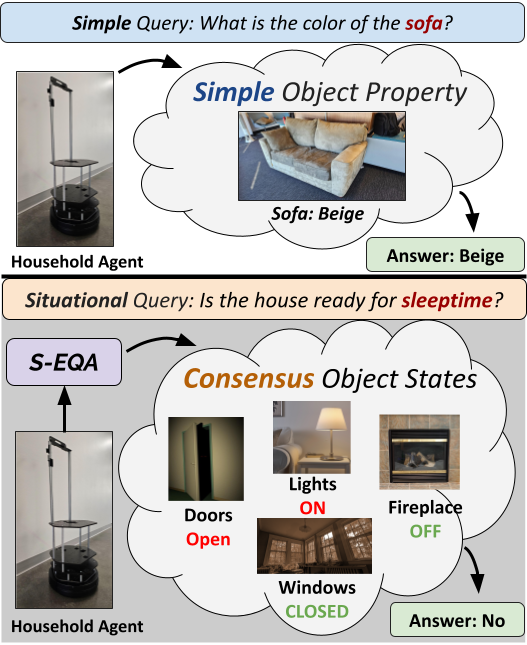
We present and tackle the problem of Embodied Question Answering (EQA) with Situational Queries (S-EQA) in a household environment. Unlike prior EQA work tackling simple queries that directly reference target objects and properties (“What is the color of the car?”), situational queries (such as “Is the house ready for sleeptime?”) are challenging as they require the agent to correctly identify multiple object-states (Doors: Closed, Lights: Off, etc.) and reach a consensus on their states for an answer.
Video
Paper
Is the House Ready for Sleeptime? Generating and Evaluating Situational Queries for Embodied Question Answering.
Vishnu Sashank Dorbala, Prasoon Goyal, Robinson Piramuthu, Michael Johnston, Reza Ghanadan and Dinesh Manocha
Improving Zero-Shot ObjectNav with Generative Communication
We propose a new method for improving Zero-Shot ObjectNav that aims to utilize potentially available environmental percepts. Our approach takes into account that the ground agent may have limited and sometimes obstructed view. Our formulation encourages Generative Communication (GC) between an assistive overhead agent with a global view containing the target object and the ground agent with an obfuscated view; both equipped with Vision-Language Models (VLMs) for vision-to-language translation. In this assisted setup, the embodied agents communicate environmental information before the ground agent executes actions towards a target. Despite the overhead agent having a global view with the target, we note a drop in performance (13%) of a fully cooperative assistance scheme over an unassisted baseline. In contrast, a selective assistance scheme where the ground agent retains its independent exploratory behaviour shows a 10% improvement.

Paper
Improving Zero-Shot ObjectNav with Generative Communication.
Vishnu Sashank Dorbala, Vishnu Dutt Sharma, Pratap Tokekar, Dinesh Manocha
LOC-ZSON: Language-driven Object-Centric Zero-Shot Object Retrieval and Navigation
In this paper, we present LOC-ZSON, a novel Language-driven Object-Centric image representation for object navigation task within complex scenes. We propose an object-centric image representation and corresponding losses for visual-language model (VLM) fine-tuning, which can handle complex object-level queries. In addition, we design a novel LLM-based augmentation and prompt templates for stability during training and zero-shot inference. We implement our method on Astro robot and deploy it in both simulated and real-world environments for zero-shot object navigation. We show that our proposed method can achieve an improvement of 1.38 - 13.38% in terms of text-to-image recall on different benchmark settings for the retrieval task. For object navigation, we show the benefit of our approach in simulation and real world, showing 5% and 16.67% improvement in terms of navigation success rate, respectively.
Video
Paper
LOC-ZSON: Language-driven Object-Centric Zero-Shot Object Retrieval and Navigation.
Tianrui Guan, Yurou Yang, Harry Cheng, Muyuan Lin, Richard Kim, Rajasimman Madhivanan, Arnie Sen, Dinesh Manocha
Can LLMs Generate Human-Like Wayfinding Instructions? Towards Platform-Agnostic Embodied Instruction Synthesis
We present a novel approach to automatically synthesize “wayfinding instructions” for an embodied robot agent. In contrast to prior approaches that are heavily reliant on human-annotated datasets designed exclusively for specific simulation platforms, our algorithm uses in-context learning to condition an LLM to generate instructions using just a few references. Using an LLM-based Visual Question Answering strategy, we gather detailed information about the environment which is used by the LLM for instruction synthesis. We implement our approach on multiple simulation platforms including Matterport3D, AI Habitat and ThreeDWorld, thereby demonstrating its platform-agnostic nature. We subjectively evaluate our approach via a user study and observe that 83.3% of users find the synthesized instructions accurately capture the details of the environment and show characteristics similar to those of human-generated instructions. Further, we conduct zero-shot navigation with multiple approaches on the REVERIE dataset using the generated instructions, and observe very close correlation with the baseline on standard success metrics (< 1% change in SR), quantifying the viability of generated instructions in replacing human-annotated data. We finally discuss the applicability of our approach in enabling a generalizable evaluation of embodied navigation policies. To the best of our knowledge, ours is the first LLM-driven approach capable of generating “human-like” instructions in a platform-agnostic manner, without training.

Paper
Can LLMs Generate Human-Like Wayfinding Instructions? Towards Platform-Agnostic Embodied Instruction Synthesis.
Vishnu Sashank Dorbala, Sanjoy Chowdhury, Dinesh Manocha
LGX: Can an Embodied Agent Find Your Cat-shaped Mug? LLM-Based Zero-Shot Object Navigation
We present LGX, a novel algorithm for Object Goal Navigation in a language-driven, zero-shot manner, where an embodied agent navigates to an arbitrarily described target object in a previously unexplored environment. Our approach leverages the capabilities of Large Language Models (LLMs) for making navigational decisions by mapping the LLMs implicit knowledge about the semantic context of the environment into sequential inputs for robot motion planning. We conduct experiments both in simulation and real world environments, and showcase factors that influence the decision making capabilities of LLMs for zero-shot navigation.

Video
Paper
Can an Embodied Agent Find Your Cat-shaped Mug? LLM-Based Zero-Shot Object Navigation.
Vishnu Sashank Dorbala, James F. Mullen Jr., Dinesh Manocha
Code
Code can be found here.
CLIP-Nav: Using CLIP for Zero-Shot Vision-and-Language Navigation
Household environments are visually diverse. Embodied agents performing Vision-and-Language Navigation (VLN) in the wild must be able to handle this diversity, while also following arbitrary language instructions. Recently, Vision-Language models like CLIP have shown great performance on the task of zero-shot object recognition. In this work, we ask if these models are also capable of zero-shot language grounding. In particular, we utilize CLIP to tackle the novel problem of zero-shot VLN using natural language referring expressions that describe target objects, in contrast to past work that used simple language templates describing object classes. We examine CLIP’s capability in making sequential navigational decisions without any dataset-specific finetuning, and study how it influences the path that an agent takes. Our results on the coarse-grained instruction following task of REVERIE demonstrate the navigational capability of CLIP, surpassing the supervised baseline in terms of both success rate (SR) and success weighted by path length (SPL). More importantly, we quantitatively show that our CLIP-based zero-shot approach generalizes better to show consistent performance across environments when compared to SOTA, fully supervised learning approaches when evaluated via Relative Change in Success (RCS).

Paper
CLIP-Nav: Using CLIP for Zero-Shot Vision-and-Language Navigation.
Vishnu Sashank Dorbala, Gunnar A Sigurdsson, Jesse Thomason, Robinson Piramuthu, Gaurav S Sukhatme